فصل سوم: شروع واقعی با دیتابیس
جدولهایی برای آپولو
در درسهای قبل این فصل، که همگی به کار با دیتابیس اختصاص داشتند، پیکربندی دیتابیس را آموختیم و سپس با مفهوم مایگرشن آشنا شدیم و اصول اولیه ساخت و ویرایش جدولها به کمک آن را فرا گرفتیم و دانستیم که چطور میتوانیم به لطف مایگرشن، فرآیند ایجاد و مدیریت ساختار جدولهای اطلاعاتی خود را به محیط کدنویسی برنامه بیاوریم و چتر سیستم کنترل نسخهی خود را بر آن بیافکنیم.
در این درس برای نخستین بار به طور جدی سراغ آپولو هوا کردنمان میرویم و از آنجا که شروع پروژهها همیشه با تعریف و راهاندازی دیتابیس آغاز میشود، این پروژه را نیز با ساخت جدولهایش کلید میزنیم.
یک شروع تمیز
بد نیست حالا که میخواهیم دست به کد شویم، همه چیز را از صفر شروع کنیم؛ یعنی از نقطهای که پیکربندی دیتابیس را انجام دادهایم، ولی هنوز هیچ مایگرشنی ننوشتهایم.
اگر برای تمرین مایگرشنی نوشتهاید و اجرا کردهاید، دیتابیس و فایلهایی که ساختهاید را به صورت دستی پاک کنید.
بهتر است محض اطمینان، از کامپوزر بخواهید تا یک بار فهرست فایلهای Autoload را بهروزرسانی کند. برای این کار، دستور زیر را در کنسول خط فرمان خود اجرا کنید.
composer dump-autoload
جدولی برای مأموریتهای فضایی
اولین جدولی که میسازیم، جدولیست که اطلاعات مأموریتهای فضایی را در آن نگهداری میکنیم.
شما اکنون میدانید که برای ساخت مایگرشن مربوط به این جدول، به چه دستور آرتیزانی نیاز داریم.
php artisan make:migration create_missions_table
و میدانید که با اجرای این دستور، لاراول کلاسی برای ما میسازد و بدنهی خام آن را تکمیل میکند.
اجازه بدهید با این پیشفرض که همراه من جلو میآیید و کارهایی که میگویم را واقعاً انجام میدهید، از نمایش تصویر اسکرینشات از اجرای دستور بالا در کنسول خط فرمان و کد تولیدشده، صرف نظر کنم و سراغ اصل مطلب برویم.
چه ستونهایی لازم داریم؟
این اولین پرسشیست که هنگام طراحی یک جدول با آن مواجه میشویم، اما اولین پرسشی نیست که باید جوابش را بیابیم. سؤال درست در این مرحله، چیز دیگری است:
چه دادههایی را قرار است نگهداری کنیم؟
این شد یک چیزی! اگر بدانیم که چه دادههایی را قرار است در جدول خود بریزیم، میتوانیم در مورد کمّ و کیف ستونهای آن نیز تصمیم درستی بگیریم.
عجالتاً فرض کنید با جستوجو در اینترنت یا پرسش مستقیم از کارفرما، به این نتیجه برسیم که هر مأموریت فضایی به دادههای زیر نیازمند است:
- کد مأموریت
- عنوان مأموریت
- سازمان مسئول
- هدف از اجرا
- شرح کوتاه مأموریت
- تاریخ آغاز
- تاریخ پایان
- وضعیت تصویب
- وضعیت اجرایی
حالا چه ستونهایی لازم داریم؟
بله. حالا که میدانیم چه دادههایی را قرار است برای یک مأموریت نگهداری کنیم، میتوانیم به ستونها فکر کنیم و به این نیازمندیها برسیم:
- یک ستون افزایش خودکار، به عنوان ایندکس اولیه که گفتیم همیشه نامش را
idمیگذاریم و همیشه در ابتدای هر جدول قرار میدهیم؛ - ستونهایی از نوع متن، برای نگهداری کد و عنوان مأموریت و سازمان مسئول و هدف و شرح کوتاه؛
- ستونهایی از نوع تاریخ برای نگهداری زمان آغاز و پایان رسمی مأموریت؛
- ستونی از نوع منطقی برای این که بدانیم مأموریت مورد نظر ما به تصویب مقامات رسیده است یا خیر؛
- ستونی برای نگهداری وضعیت اجرایی
وضعیت اجرایی
این ستون وضعیت اجرایی کمی دردسرساز است. کارفرما میگوید که وضعیت اجرایی یکی از حالتهای «در حال برنامهریزی»، «در حال اجرا»، «موفقیتآمیز» و «شکستخورده» است و چیزی جز این چهار حالت وجود ندارد. پس ما میتوانیم یک ستون متنی برای وضعیت در نظر بگیریم و یکی از همین چهار حالت را در آن ذخیره کنیم یا به هر کدام از حالتها عددی را اختصاص دهیم و آن عدد قراردادی را در یک ستون از نوع عددی ذخیره کنیم.
اما راه بهتری هم وجود دارد:
به ازای هر کدام از این چهار وضعیت، یک ستون مستقل از نوع زمان در نظر میگیریم و تاریخ و ساعت وقوع هر یک از این وضعیتها را در آن ثبت میکنیم:
- زمان شروع برنامهریزی
- زمان شروع اجرا
- زمان پایان موفقیتآمیز
- زمان شکست
به این ترتیب، از نحوهی پر شدن این ستونها میتوانیم به وضعیت مأموریت پی ببریم و این کار را در لایهی مدل برنامهی خود انجام میدهیم.
طبیعتاً یک مأموریت نمیتواند هم موفقیتآمیز باشد و هم شکستخورده تلقی شود و یکی از دو ستون پر میشود و به دیگری نیازی نیست. فعلاً نگران این موضوع نباشید و به این فکر کنید که تفکیک وضعیت اجرایی به چهار ستون زمانی، ما را از دست ستونهای مبهم آغاز و پایان نیز خلاص میکند.
متد بالارونده
حالا میتوانیم دست به کیبورد شویم و کد آنچه را که لازم داریم، بنویسیم. در متد بالارونده، موسوم به up، ترتیب برپا کردن جدول را میدهیم.
کد بالاروندهی شما باید چیزی به شکل زیر شود، هرچند میدانید که همهی این کد را لازم نیست خودتان بنویسید. کنسول آرتیزان بخشهایی را از قبل برای شما نوشته بود.
public function up()
{
Schema::create('missions', function (Blueprint $table) {
$table->increments('id');
$table->string('code')->index();
$table->string('title')->index();
$table->string('operator')->index();
$table->mediumText('purpose')->nullable();
$table->text('description')->nullable();
$table->boolean('is_ratified')->default(false);
$table->timestamp('planned_at')->nullable()->index();
$table->timestamp('started_at')->nullable()->index();
$table->timestamp('succeeded_at')->nullable()->index();
$table->timestamp('failed_at')->nullable()->index();
$table->timestamps();
$table->softDeletes();
});
}
پیش از آن که به خواندن ادامه دهید، کمی تأمل کنید و سعی کنید تکتک خطهای قطعه کد بالا را برای خود تفسیر کنید که هر کدام چه میکنند.
ما در این کد، علاوه بر آنچه که برنامهریزی شد، جزئیات دیگری را هم رعایت کردیم.
- تمام ستونهایی که به نظر میرسید ممکن است به مرتبسازی و جستوجو نیاز داشته باشند را با استفاده از متد زنجیرهای
()index، ایندکسگذاری کردیم. - تمام ستونهایی که به نظر میرسید ممکن است اختیاری باشند را با استفاده از متد زنجیرهای
()nullable، علامت زدیم تا بتوانند مقدار خالی را ذخیره کنند و غیبت اطلاعات، ما را با مشکلی مواجه نسازد. - ستون منطقی وضعیت تصویب را به کمک متد زنجیرهای
()defaultبا یک مقدار پیشفرض پر کردیم. - به کمک متد
()timestamps(خط ۱۵) دو ستون برای نگهداری زمان ایجاد و آخرین بهروزرسانی هر رکورد اضافه کردیم. (لاراول، خودش، ترتیب بقیهی کارها را میدهد.) - به کمک متد
()softDeletes(خط ۱۶) ستونی به نامdeleted_atبرای ایجاد قابلیت زبالهدان ایجاد کردیم. (لاراول ترتیب این یکی را هم میدهد.)
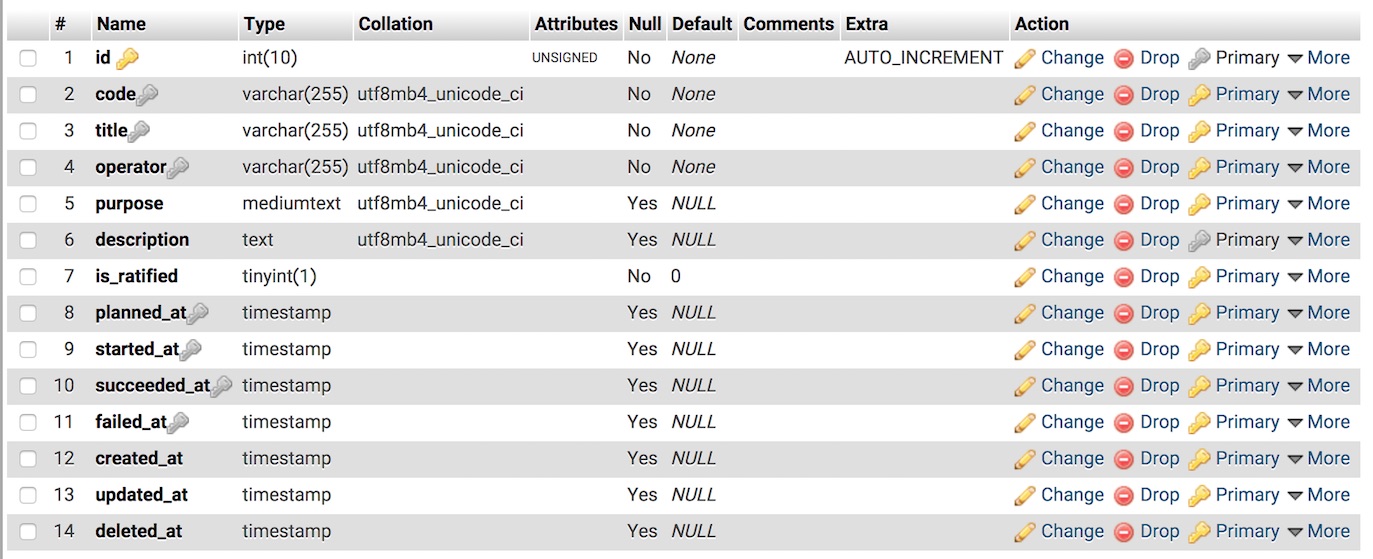
اجرای این مایگرشن در دیتابیس mySql، باید جدولی به این شکل برای شما ایجاد کند.
متد پایینرونده
یادتان هست که در متد پایینرونده باید چه کار میکردیم؟
هر آنچه در متد up ساخته شده، میبایست در متد down از بین برود تا عملکرد عقبگرد در مایگرشن بهخوبی انجام شود.
متد بالاروندهی مایگرشن ساخت مأموریتهای ما، جدول را برپا ساخته بود و متد پایینرونده باید آن را نابود کند.
public function down()
{
Schema::dropIfExists('missions');
}
اگر با من جلو آمده باشید، متوجه شدهاید که این خطها از قبل توسط آرتیزان نوشته شده بودند!
جدولی برای اطلاعات آدمها
از آنجا که تقریباً تمام پروژههای وب در عالم امکان به جدولی برای نگهداری اطلاعات کاربران نیاز دارند، لاراول مایگرشن سادهای برای جدول users را در جعبهی خود گذاشته که در بدو نصب، قابل استفاده است.
متد up این مایگرشنِ حاضر و آماده، به شکل زیر است:
public function up()
{
Schema::create('users', function (Blueprint $table) {
$table->increments('id');
$table->string('name');
$table->string('email')->unique();
$table->string('password');
$table->rememberToken();
$table->timestamps();
});
}
به دستور ساخت ستون id در ابتدای کد، و متد ()timestamps در انتهای آن توجه کنید و به خاطر بسپارید که در مایگرشنهایی که خودتان هم مینویسید این الگو را رعایت کنید تا ساختار دیتابیسی یکپارچه و استاندارد داشته باشید.
ستونی که با متد ()rememberToken ساخته میشود، رشتهای صد کاراکتری در خود جای میدهد که به درد گزینهی «مرا به خاطر بسپار» زیر فرمهای لاگین میخورد و لاراول، خودش ترتیب استفاده از آن را میدهد.
اجرای مایگرشن در همین وضعیتی که هست (یعنی اجرای دستور php artisan migrate در کنسول خط فرمان)، جدولی به شکل زیر برای ما میسازد:
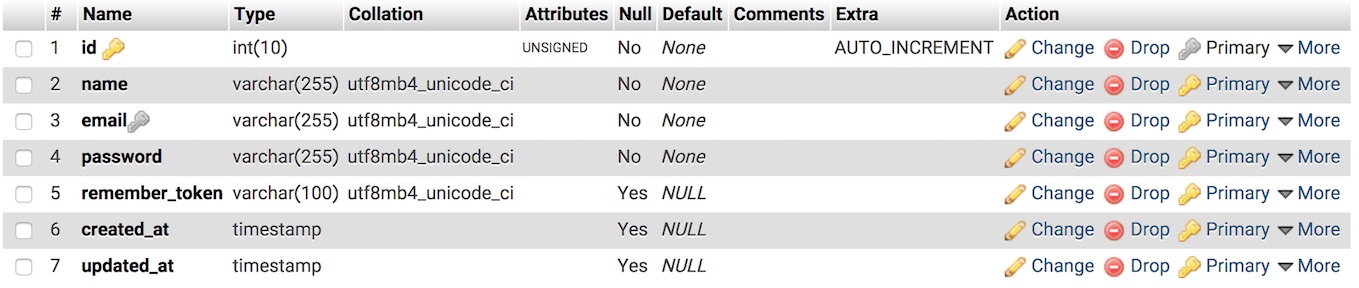
اما این همهی چیزی نیست که ما میخواهیم.
دادههای مورد نیاز ما
فرض کنید که یک بار دیگر، مستندات سفارش کارفرمای فرضی را میکاویم و میفهمیم که در جدول مورد نیاز برای نگهداری اطلاعات آدمها، به این دادهها نیاز داریم:
- نام و نام خانوادگی
- شماره ملی، که در صورت لزوم به عنوان نام کاربری هم مورد استفاده قرار بگیرد
- رمز عبور
- نشانی ایمیل که بتواند تکراری باشد
- سن
- عنوان شغلی
- وضعیت شغلی (فعال هست یا خیر)
ستونهای مورد نیاز ما
- یک ستون افزایش خودکار، به عنوان ایندکس اولیه لازم داریم که طبق معمول همیشه نامش را
idمیگذاریم و در ابتدای جدول قرار میدهیم؛ - از آنجا که نام و نام خانوادگی به صورت جداگانه قید شده، یک ستون را برای نام، و ستون دیگری را برای نام خانوادگی لازم داریم و طبیعتاً هر دو را از نوع رشتهای (VARCHAR) میخواهیم.
- شمارهی ملی همیشه عددی یازده رقمی است، اما چون ماهیت عددی ندارد و قرار نیست با چیزی جمع و تفریق شود، ما آن را هم به صورت رشتهای در نظر میگیریم تا اگر صفری هم اول آن است، از بین نرود.
- رمز عبور برای امنیت بیشتر باید هش شود و اگر بخواهیم از سرویس هش لاراول استفاده کنیم، باید حداقل ۶۰ کاراکتر جا در نظر بگیریم.
- نشانی ایمیل به صورت رشتهای است و حالا که قرار است تکرارپذیر باشد، باید از شر ایندکس یکتای آن خلاص شویم.
- سن عددی است معمولاً دو رقمی که هر سال عوض میشود. درست است که کارفرما به سن آدمها نیاز داشته، اما ما عقل داریم و به جای آن که سن مردم را ذخیره کنیم، تاریخ تولدشان را ذخیره میکنیم تا لازم نباشد هر سال آن را تغییر دهیم.
- برای راحتی کار فرض میکنیم که عنوان شغلی یک کلمه است تا خودمان را بیش از آنچه که نیاز است درگیر روابط پیچیدهی جدولها نکنیم.
- وضعیت شغلی یک متغیر منطقی است که میتواند مقدار «درست» یا «غلط» بگیرد، اما این حالت خیلی شبیه همان سیستم زبالهدانی است که لاراول در اختیار ما گذاشته و بلوپرینت متد ویژهای برای ساختن آن در نظر گرفته است.
ساخت مایگرشن
برای یک پروژهی صفرکیلومتر، هیچ اشکالی ندارد که همان مایگرشن پیشفرض لاراول که برای کاربران ساخته بود را باز کنیم و تغییرات مورد نظرمان را در همان کلاس اعمال کنیم. اما حالا که میخواهیم چیزی یاد بگیریم، بد نیست یک مایگرشن ویرایشگر بسازیم و تغییرات را در مایگرشن خودمان اعمال کنیم.
برای ساخت فایل مایگرشن، از دستور آرتیزان کمک میگیریم که شما هنگام خواندن این متن، قاعدتاً میدانید که آن دستور چیست و اگر هم یادتان رفته، میدانید که کجا دنبالش بگردید.
php artisan make:migration modify_users_table --table=users
این را هم دیگر میدانید که آرتیزان پس از دریافت این دستور، چه کارهایی را برای ما انجام میدهد:
- فایلی میسازد که نام آن ترکیبی از تاریخ و یک عدد ترتیبی و نام جدولی است که انتخاب کردهایم. نام این فایل برای من، چنین شده که بخش نخست آن قطعاً برای شما تفاوت دارد.
2018_02_28_173803_modify_users_table
فایلی که ساخته را در سر جای درستش، یعنی
database/migrationsقرار میدهد.کلاسی با نام
ModifyUsersTable(یعنی صورت studly_case از همان اسمی که انتخاب کردیم) میسازد و متدهایupوdownرا در آن جای می دهد و برای آن که لطف را تکمیل کرده باشد، کامنتهای PHPDoc را هم بالای هر دو متد قرار میدهد.تابع
Schema::tableرا در هر دو متد قرار میدهد و نام جدول ما (users) را به عنوان آرگومان اول آن قرار میدهد و بستاری با آرگومان بلوپرینت را در ادامه فراخوانی میکند.و چون نمیداند که میخواهیم چه کار کنیم، داخل این بستار (Closure) را خالی میگذارد.
متد بالارونده
در متد بالارونده، موسوم به up، ترتیب برپا کردن سازهای را میدهیم که این بار از نوع ساخت جدول نیست، بلکه قرار است چیزهایی تغییر کند.
اجازه بدهید برای یادآوری، یک بار دیگر متد up موجود در مایگرشن ساخت جدول کاربران را مرور کنیم (همان که از اول در بستهی لاراول وجود داشت).
public function up()
{
Schema::create('users', function (Blueprint $table) {
$table->increments('id');
$table->string('name');
$table->string('email')->unique();
$table->string('password');
$table->rememberToken();
$table->timestamps();
});
}
حالا میتوانیم آنچه که نیازمند تغییر است را در مایگرشن خودمان تعریف کنیم.
- به ستون
idکاری نداریم و میگذاریم همین طور که هست، به حال خودش باشد. - ستون
nameکار ما را راه نمیاندازد، چون قرار است نام و نام خانوادگی را به صورت جداگانه ذخیره کنیم. - ستون
emailرا لازم داریم، اما قرار است یکتا نباشد. - ستونهای مربوط به رمز عبور و تاریخها، به همین ترتیب فعلی، برای ما کفایت میکنند و کاری به کارشان نداریم.
- سایر چیزهایی که لازم داریم، در جدول وجود ندارند و باید توسط ما ایجاد شوند.
public function up()
{
Schema::table('users', function (Blueprint $table) {
$table->dropColumn('name');
$table->string('first_name')->after('id');
$table->string('last_name')->after('first_name');
$table->timestamp('birthday')->index()->nullable()->after('email');
$table->string('code_melli')->unique()->after('birthday');
$table->string('position')->index()->after('code_melli');
$table->softDeletes();
$table->dropUnique('users_email_unique');
$table->index('email');
$table->index(['last_name' , 'first_name'] , 'users_name_index');
});
}
خیلی جدی، سعی کنید پیش از آن که سطرهای بعد را مطالعه کنید، یکایک خطهای قطعه کد کوچک بالا را برای خود بخوانید و حدس بزنید که هر کدام چه میکنند.
اجرای مایگرشن بالا (یعنی اجرای دستور php artisan migrate در کنسول خط فرمان)، باید جدولی به شکل زیر برای شما بسازد:
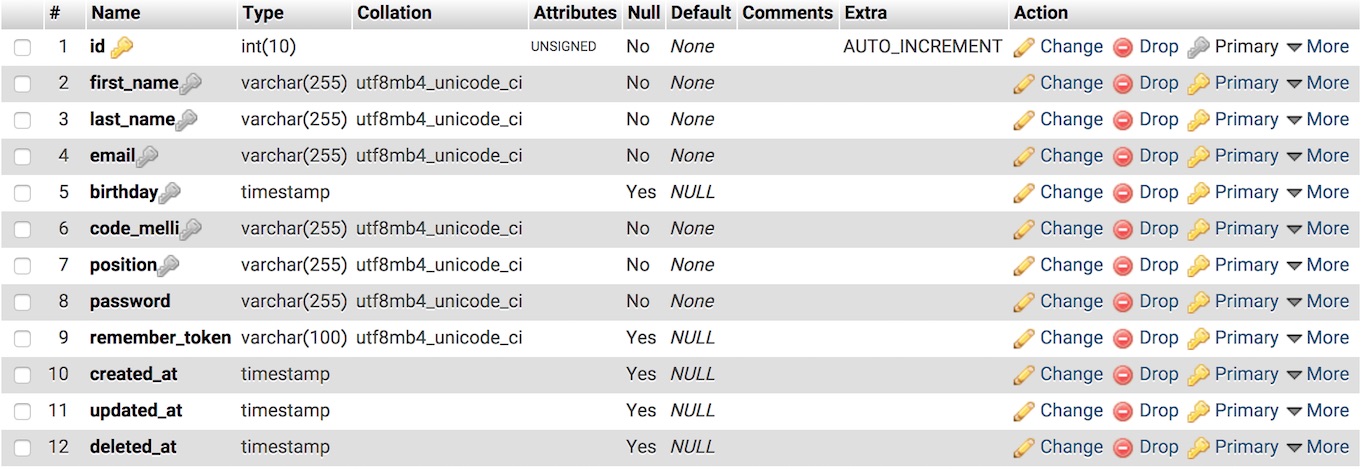
خطهای اول و دوم و سوم را میشناسیم و به جزئیاتشان نمیپردازیم. اینها همانهایی هستند که از اول توسط کنسول آرتیزان نوشته شده بودند.
در خط چهارم، ستون name را پاک کردیم و از دستش خلاص شدیم.
در خطهای پنجم و ششم، ستونهایی برای «نام» و «نام خانوادگی» ایجاد کردیم. بعد در خطهای هفتم و هشتم و نهم، ستونهایی را که از قبل وجود نداشتند، برای تاریخ تولد و کد ملی و موقعیت شغلی ساختیم و با استفاده از متد زنجیرهای ()after جایشان را در جدول مشخص کردیم، چون هیچ کس از جدول شلخته خوشش نمیآید.
در خط ۱۰ ستون زبالهدان را با عنوان deleted_at ساختیم که ما زحمت زیادی برای آن نکشیدیم.
در خط ۱۴ و ۱۵، ایندکس یکتای ستون ایمیل را، بنا بر سفارش کارفرما، با ایندکس معمولی جایگزین کردیم.
توجه کنید که متد ()dropUnique به جای نام ستون، به دنبال نام ایندکسی است که روی ستون قرار داده شده است. ما معمولا هنگام تعریف ایندکسها در مایگرشن، حال و حوصلهی تخصیص نام برای آن را نداریم (مثل خط ۱۵ خودمان) و لزومی هم ندارد، اما ایندکسها در جداول بانک اطلاعاتی بدون نام ایجاد نمیشوند.
بلوپرینت، نامی پیشفرض برای ایندکسها در نظر میگیرد که این نام، برای ایندکس معمولی مثل چیزی که در خط ۱۵ ایجاد شده، users_email_index است. در واقع ترکیبی از نام جدول، نام ستون، و نوع ایندکس را به عنوان نام برمیگزیند.
در خط ۱۴، با همین فرمول به نام users_email_unique دست پیدا کردیم که البته راه راحتتری هم برای آن وجود داشت! کافی بود نام ایندکس را از برنامهای مثل phpMyAdmin، نگاه کنیم که پیش از اجرای مایگرشن ویرایش ما، به شکل زیر است:
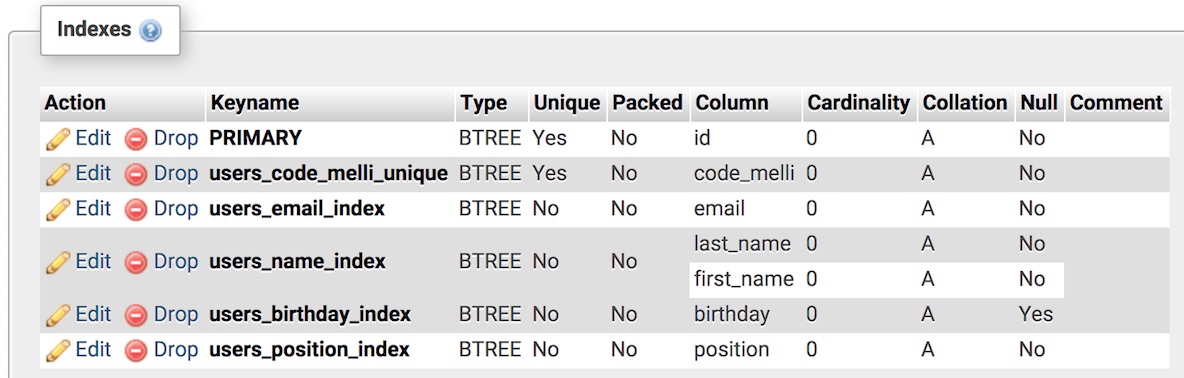
به یاد دارید که گفتیم همهی دادههایی که ممکن است مورد مرتبسازی یا جستوجو قرار گیرند، بهتر است ایندکس هم بشوند. ما هم با استفاده از متد زنجیرهای ()index همین کار را کردیم. اما «نام» و «نام خانوادگی» دو ستون جداگانه هستند که بهتر است با هم، یکجا ایندکس شوند. خط ۱۶ همین کار را میکند و برای آن که ثابت کنیم خودمان هم میتوانیم روی ایندکسهایمان اسم بگذاریم، نام users_name_index را در آرگومان دوم به آن پاس دادیم.
حدس میزنید اگر خودمان عنوانی برای این ایندکس انتخاب نمیکردیم، بلوپرینت چه اسمی بر آن میگذاشت؟ (پیشنهاد میکنم به حدس زدن اکتفا نکنید و عملاً آزمایش کنید.)
متد پایینرونده
رسم است که توسعهدهندگان تازهوارد به دنیای مایگرشن، وقتی نوبت نوشتن متد down میرسد، گیج شوند و بترسند و ندانند که چه باید بکنند. اگر از آن دسته انسانهایی هستید که به رسم و رسوم احترام میگذارند، شما هم ادای گیج شدن و ترسیدن را دربیاورید، اما در دلتان با خیال راحت به آنها لبخند بزنید، زیرا میدانید ایدهی متد پایینرونده خیلی سادهتر از آن است که هراس ایجاد کند.
هر آنچه در متد up ساخته شده، میبایست در متد down از بین برود تا عملکرد عقبگرد در مایگرشن بهخوبی انجام شود.
به این صورت:
public function down()
{
Schema::table('users', function (Blueprint $table) {
$table->string('name')->after('id');
$table->dropUnique('users_email_index');
$table->unique('email');
$table->dropColumn([
'first_name',
'last_name',
'birthday',
'code_melli',
'position',
'deleted_at'
]);
});
}
در خط ۴ ستون name که دور انداخته بودیم را سر جایش گذاشتیم، در خط ۶ و ۷ ایندکس را به همان حالت ایندکس یکتای قبلی بازگرداندیم، و در ادامه، تمام ستونهایی که ساخته بودیم را از بین بردیم.
لازم نیست ایندکس نام را هم پاک کنیم. خودش با حذف ستونهای «نام» و «نام خانوادگی» از بین میرود.
به عنوان تمرین، سعی کنید فقط یکی از دو ستون «نام» یا «نام خانوادگی» را پاک کنید و ببینید چه بر سر ایندکسی که از هر دو استفاده میکرده میآید.
به این ترتیب، متد پایینرونده، هر چه که در متد بالارونده انجام شده بود را بیاثر ساخت و به اصطلاح جوانان امروزی، undo کرد.
یک مرور کلی
بعد از نگارش مایگرشنهایی که در این درس آموختیم، میتوانیم یک بار دستور مایگرت را اجرا کنیم و ببینیم چه گیرمان آمده است.
php artisan migrate
شاید مثل من بخواهید یک بازسازی کلی، بدون توجه به آنچه تاکنون ساخته شده، انجام دهید.
php artisan migrate:fresh
چه اتفاقی میافتد؟
لاراول جدولهایی مطابق نیاز ما و بر اساس نسخهای که ما نوشتیم میسازد و نتیجهی اجرای این دستورات را در جدولی به نام migrations ذخیره میکند. در درس پیکربندی دیتابیس آموختیم که نام این جدول را میتوانیم تغییر دهیم، اما معمولاً نیازی نیست.
جدول migrations ما باید به شکل زیر درآمده باشد:
عکس بالا در حالی گرفته شده که میخواستم به آنچه در ستون batch ذخیره شده بود دست بزنم و تغییرش بدهم. واقعیت آن است که این کار «جرزنی» محسوب میشود و به هیچ دردی نمیخورد و هیچ کاربردی ندارد؛ جز تمرین و آزمایش.
دست به کار شوید و همین عمل را انجام بدهید و بعد دستور php artisan migrate:rollback را اجرا کنید و ببینید که چطور لاراول گول میخورد و فقط جدول users را یک گام به عقب میبرد و به حالت ابتدایی آن درمیآورد.
بد نیست برای تمرین، نگاه دوبارهای به درس درک مفهوم مایگرشن بیاندازید و با استفاده از تعالیم آن درس و جرزنیای که اشاره کردم، کمی در نوار زمان مایگرشن عقب و جلو بروید و ساختار جدولهایتان را تماشا کنید.
در این نقل و انتقالات چه بر سر دادهها میآید؟
میخواهید چطور شود؟
دادههایی که در ستونهایی که دور میریزیم بودهاند، دور ریخته میشوند!
اطلاعات از دست رفته، قابل بازیافت هستند؟
نه! به هیچ وجه!
ولی زیاد نگران نباشید و نترسید.
عمل migrate، کاری نیست که در زمان اجرای برنامه انجام شود. این کارها فقط در فازهای توسعه روی میدهند که همه چیز تحت کنترل برنامهنویس است و یک برنامهنویس خوب میداند که پیش از اقدامات انتحاری روی دادهها باید ترتیب انتقال امن و امان آنها را داده باشد.
جان کلام
در این درس، جدول missions را ایجاد کردیم و در جدول users تغییراتی دادیم که مطابق میل ما شوند. کار آپولوی ما البته با همین دو جدول راه نمیافتد و جدولهای دیگری را هم به مرور خواهیم افزود.
در این میان، امیدوارم دقت کرده باشید که تمام ستونهای تاریخدار را به صورت nullable ساختیم و هر چیزی که ممکن بود مورد جستوجو قرار گیرد را ایندکس کردیم. اما بعید است جمع بودن اسم جدولها توجه شما را جلب کرده باشد. ما در لاراول، نام همهی جدولهایمان را به صورت جمع انتخاب میکنیم تا با ماهیت آنها سازگار باشد: users محلی برای نگهداری اطلاعات userهاست و missions، محلی برای نگهداری اطلاعات missionها.
ماجرای این فصل را همین جا به پایان میرسانیم و در فصل پنجم که کار با لایهی مدل را آغاز میکنیم، به سراغ مایگرشنهایمان میآییم و مدلهای معرکهای برای این جدولها میسازیم.